

By Adria Seccareccia, Library/Archivist, and Alexandra Kohn, Digital Collections & Copyright Librarian.
What does preserving born-digital content look like? If you pictured a baby robot safely stored away for posterity in a virtual safe, we’re afraid you are not quite right. Websites are a perfect example of this type of content – things that are natively digital, rather than a digitized version of a physical item. Libraries and archives today have the challenge of capturing and curating born-digital content and one way to do this is through web archiving. McGill has just launched a new web archiving collection documenting McGill University’s responses to Anti-Black Racism.
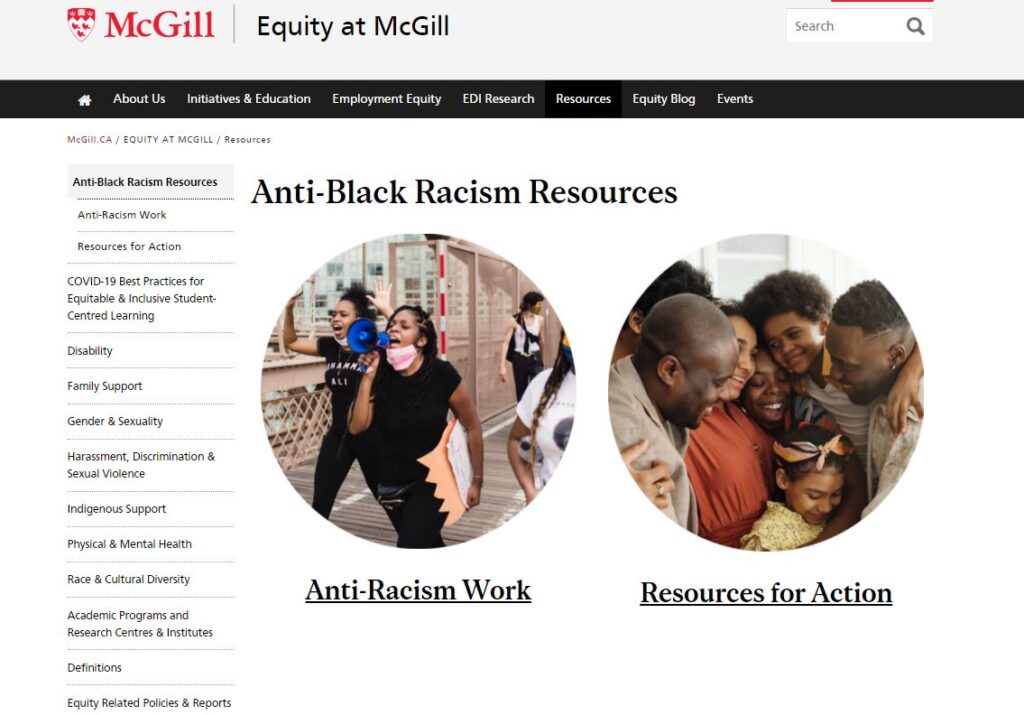
The McGill University Library is excited to share the launch of a new web archives collection entitled McGill University Responses to Anti-Black Racism. The collection seeks to capture web content that documents McGill University’s responses to Anti-Black Racism, specifically within the context of the 2020 conversations around Black Lives Matter and calls to address Anti-Black Racism and systemic racism. Sites and pages captured include content created by McGill University communications, faculties, departments, researchers, staff and students, but also responses from student associations and publications on how the University has addressed Anti-Black Racism in the past and the measures it began taking in 2020 and onwards.

So how do we archive web content?
To archive web content, we use Archive-IT, a web archiving subscription service that allows us to capture content but also the look and feel of web pages. This might not seem like a big deal now, since these pages are currently available online, but in the future, when sites are taken down or updated, researchers will be able to see what the original pages were like at the time they were captured.
This is also why, as you browse the collection, you will notice that some pages are captured multiple times. Since the content of certain pages or sites change over time we schedule a ‘crawl’ to capture the page at regular intervals to ensure changes are documented. Think of the difference between an article in The McGill Daily, for which the content will likely never change, and a Facebook page, where content is constantly changing.
Example of a web site captured multiple times

How do we choose what we capture?
When we first started this collection we scoured the internet looking for relevant content that fit the collection’s scope. We also documented our decisions, for instance why does x content fit the collection? Or, in certain instances, did we receive permission to capture content? Just because it’s on the internet does not mean creators intend for their content to be archived. There were also technical hiccups along the way; unfortunately, some pages aren’t as easily captured as others, but with time this will only improve.
So far we’ve captured 30 pages/sites for this collection alone, but it doesn’t end here! This is a living collection and we continue to capture pages as content is created.
You can access the collection directly through Archive-It or through McGill Library’s catalogue.
Do you have questions about McGill Library’s web archiving project? Adria Seccareccia and Alexandra Kohn would love to hear from you!
Mesures prises par McGill pour répondre à le racisme anti-Noirs : Un nouveau projet d’archivage Web voit le jour!
Par Adria Seccareccia, Bibliothécaire/Archiviste, Alexandra Kohn, Bibliothécaire des collections numériques et des droits d’auteur
À quoi peut bien ressembler la conservation de contenu numérique? Si vous imaginez un bébé robot entreposé bien en sécurité dans un coffre-fort virtuel pour la postérité, vous êtes malheureusement dans l’erreur! Les sites Web sont de parfaits exemples du type de contenu visé – c’est-à-dire du contenu créé sous forme numérique, plutôt qu’une version numérisée d’un document physique. Les bibliothèques et les archives d’aujourd’hui doivent relever le défi de capturer et d’assurer la conservation du contenu numérique original, et l’une des façons de le faire est d’archiver les sites Web. McGill vient tout juste de mettre sur pied une nouvelle collection d’archivage Web qui documente les réponses de l’Université McGill au racisme anti-Noirs.
La bibliothèque de l’Université McGill est fière d’annoncer le lancement d’une nouvelle collection d’archivage Web, appelée McGill University Responses to Anti-Black Racism, qui porte sur les réponses de l’Université McGill au racisme anti-Noirs, notamment dans le contexte des discussions de 2020 autour du mouvement Black Lives Matter et des appels à éliminer le racisme anti-Noirs et le racisme systémique. Les sites et les pages Web capturées comprennent le contenu créé par le Service des communications, les facultés, les départements, les chercheurs, le personnel et les étudiants de l’Université McGill, mais aussi les réponses des associations étudiantes et les publications portant sur la façon dont l’Université a traité les questions liées au racisme anti-Noirs par le passé et sur les mesures qu’elle a commencé à mettre en œuvre en 2020.
Comment archive-t-on du contenu Web?
Pour archiver du contenu Web, nous faisons appel à Archive-IT, un service d’archivage Web par abonnement qui nous permet de capturer non seulement le contenu, mais aussi la présentation des pages Web. Cela ne semble peut-être pas important aujourd’hui, puisque ces pages sont encore accessibles en ligne, mais dans l’avenir, lorsque les sites seront fermés ou mis à jour, les chercheurs pourront les voir dans leur format original, tels qu’ils étaient au moment où ils ont été capturés.
C’est aussi pour cette raison que vous remarquerez, en parcourant la collection, que certaines pages ont été capturées plusieurs fois. Comme le contenu des pages et des sites Web change au fil du temps, nous planifions un crawl récurrent utilisant un « robot de collecte » qui capture les pages à intervalles réguliers, afin que tous les changements soient documentés. Pensez à la différence entre un article du McGill Daily, dont le contenu ne change pratiquement jamais, et une page Facebook, dont le contenu change constamment.
Exemple d’un site Web capturé plusieurs fois
Comment choisit-on le contenu à capturer?
Quand nous avons instauré cette collection, nous avons parcouru Internet à la recherche de contenu pertinent à l’objectif. Nous avons en outre consigné nos décisions, par exemple les motifs justifiant l’intégration d’un contenu particulier à la collection, ou encore, dans certains cas, si nous avons obtenu l’autorisation de capturer le contenu. En effet, le simple fait qu’un contenu soit diffusé dans Internet ne signifie pas que ses créateurs autorisent son archivage. Nous avons aussi connu quelques ratés techniques en cours de route; malheureusement, certaines pages ne sont pas aussi faciles à capturer que d’autres, mais avec le temps, les choses finiront par s’améliorer.
Nous avons jusqu’à maintenant capturé 30 pages et sites rien que pour cette collection, mais nous ne nous arrêterons pas là! Il s’agit d’une collection évolutive, et nous continuerons d’y ajouter les pages capturées à mesure qu’elles sont créées.
Vous pouvez consulter la collection directement sur le site Archive-It ou par l’entremise du catalogue de la bibliothèque de McGill.
Vous avez des questions au sujet du projet d’archivage Web de la bibliothèque de McGill? Adria Seccareccia et Alexandra Kohn seront ravies d’y répondre!










Leave a Reply
You must be logged in to post a comment.